
OSTALI SEMINARSKI RADOVI
IZ INTERNET - WEBA |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

Analiza linkova
 Pronalaženje
informacija na WWW-u je jedan od najizazovnijih
zadataka. U početku je rad na pronalaženju informacija bio koncentrisan
na sadržaj hiperteksta, i malo je pažnje bilo posvećeno hipervezama
(hiperlinkovima) koji povezuju različite dokumente.
Pronalaženje
informacija na WWW-u je jedan od najizazovnijih
zadataka. U početku je rad na pronalaženju informacija bio koncentrisan
na sadržaj hiperteksta, i malo je pažnje bilo posvećeno hipervezama
(hiperlinkovima) koji povezuju različite dokumente.
Tema kojom ćemo se baviti, analiza linkova, popularna je u oblastima kao
što su društvene mreže, bezbednost računara...
Ona je deo Web mining-a, čija literatura tradicionalno definiše link(vezu)
kao usmereni hiperlink za povezivanje jedne Web strane na drugu. Sa pojavom
tehnologija kao što su semantički bogati programski jezici za označavanje
i skript jezici (npr Java Script), predstavljanje
informacija o podacima na Web-u se izuzetno promenila, što je rezultiralo
u daljem proučavanju Web mining-a za ovu vrstu podataka koja
je bogata informacijama.
U ovom radu ćemo opisati i neki od najvažnijih modela i algoritama koje
primenjuje analiza linkova, kao i aplikacije(primene) koje proističu iz
istraživanja u ovoj oblasti.
U narednim stavkama ćemo prvo nesto reći o oblastima kojima analiza linkova
pripada - Data Mining-u i Web mining-u, koji je deo Data mining-a.
Data Mining
Data mining je proces „rovarenja” po
sirovim informacijama uz pomoć kompjutera i vađenja njihovog značenja.
Zahvaljujući data mining-u, možemo da predvidimo trend
tržišta ili ponašanje konzumenata i na taj način obezbedimo uspeh firme
ili proizvoda. To se postiže analizom podataka iz raznih perspektiva i
pronalaženjem veza i odnosa između naizgled nepovezanih informacija.
Povezanost, tačnije analogija sa rudarstvom je očigledna. U potrazi za
plemenitom rudom koja je sakrivena negde duboko u planini, neophodno je
duboko kopati, izbaciti velike količine zemlje i kamena (jalovine), a
kada se jednom naiđe na žilu, neophodno je pratiti je celom dužinom.
Zbog svega gore navedenog, proces Data mining-a neraskidivo
je vezan za računare.
Web mining
Web mining, ili rudarenje Web-a, je deo rudarenja podataka(gore
opisanog Data mining-a) specijalizovan za otkrivanje podataka na internetu,
posebno na WWW-u. Web mining je oblast koja najviše obećava, jer je internet
moćan izvora informacija.
Web mining je izvlačenje interesantnih i korisnih šablona i implicitnih
informacija iz aktivnosti kao što smo rekli vezanih za WWW (World Wide
Web). Glavni zadatak koji obavlja Web mining je dobavljanje Web dokumenata,
selekcija i obrada informacija sa interneta, pronalaženje i analiza šablona
na sajtovima ili između sajtova.
Ogromne baze podataka bogate su podacima, ali i siromašne informacijama
koje su skrivene u sačuvanim podacima. Web mining je integracija informacija
prikupljenih od strane tradicionalnih metoda i tehnika Data mining-a,
sa informacijama prikupljenim na WWW-u. Služi za razumevanje ponašanja
kupaca, ocenjivanja efikasnosti neke Web stranice i pri određivanju uspešnosti
neke marketinške kampanje.
Web mining može biti kategorizovan u tri oblasti
- Mining web sadržaja (Content mining),
- Mining web structure (Structure mining), i
- Mining korišćenja web-a (Usage mining).
Od gore navedenih, nama je najbitnija oblast mining-a Web structure, s obzirom da se ona bavi analizom linkova.
Postoje i problemi kod rudarenja Web-a. Sama tehnologija Web mining-a ne uzrokuje nikakve probleme, ali korišćenje te tehnologije na ličnim podacima može da načini štetu. Najveći takav problem bi bio narušavanje privatnosti. Privatnost se narušava kada se informacije o nekom pojedincu dobijaju i koriste bez njegovog znanja i dopuštenja. Još jedan takav problem je da kompanije koje prikupljaju podatke za neku određenu svrhu, mogu te podatke koristiti za nešto sasvim drugačije. Te kompanije su odgovorne za sva izdavanja tih podataka, i ako se primete nekakve nepravilnosti sledi im sudska tužba, ali nema zakona koji ih sprečava da trguju tim podacima. Kako popularnost WWW-a i dalje raste, postoji rastuća potreba za razvijanjem novih alata i tehnika koje će poboljšati njegovu celokupnu korisnost.
2. Analiza linkova
Analiza linkova je deo šireg istraživanja u oblasti Data mining-a poznata kao Web rudarstvo(Web mining), što je proces primene Data mining tehnika za izdvajanje korisnih informacija sa Web-a.2.1 Analiza linkova u Web Mining-u
U analizi linkova, mi smo pre svega zainteresovani za oblast Web structure
mining (Mining web strukture).
Web structure mining, jedna od tri kategorije Web mining-a koje smo spomenuli,
je alat koji se koristi za identifikaciju odnosa između Web stranice povezane
informacijom ili direktnim linkom. Ova struktura podataka se otkriva odredbom
šemi Web struktura kroz tehnike baze podataka za Web stranice. Ova konekcija
omogućava pretraživaču da povuče podatke, koji se odnose na upit za pretragu,
direktno na Web stranicu koja linkuje sa Web lokacije na kojoj sadržaj
počiva.
Analiza linkova može biti obogaćena uklapanjem u podatke iz svih kategorija
Web mining-a. Neki primeri kako analiza linkova može da se koristi sa
i bez dodatnih Web mining podataka:
• Dodeljivanje ovlašćenja kolekciji Web strana. U kombinaciji sa sadržajem
Web podataka, vlast može biti podeljena u skladu sa sadržajem teme.
• Razumevanje Web graf strukture kroz ispitivanje raznih graf obrazaca,
kao što su „cocitations“, „coreferences“, bipartitni
grafovi(graf čiji se čvorovi mogu podeliti u dva nesrazmerna seta U i
V, tako da svaka ivica povezuje temena u U jednom u V, to jest, U i V
su dva nezavisna seta), itd.
• Poboljšanje efikasnosti crawling-a (proces za indeksiranje kolekcije
Web stranica) tako što se raspoređuju stranice koje treba da budu „crawled”
pre drugih, kako glasi prema različitim link analizama generisanih metrika.
• Kad je kombinovan sa Web usage mining-om, analiza linkova može da se
koristi za predviđanje korisnik – trenutno(user browsing) ponašanje i
poboljšanje preporuka sistema.
2.2 Web kao graf
Pošto obrađujemo temu, kako i sam naziv kaže, koja se bavi analizom linkova
neophodno je da se malo bolje upoznamo sa pojmom na kojem se linkovi i
sreću - WWW – World
Wide Web.
WWW se može prikazati kao hijerarhija Web objekata koja se može videti
na slici. WWW se posmatra kao skup Web lokacija, a Web sajt kao skup Web
stranica sa lukovima i sadržajnim elementima. Fokusiraćemo se na Web sajt
koji je modelovan kao usmeren graf sa Web čvorovima i Web lukovima, gde
Web čvorovi odgovaraju HTML datotekama sa sadržajem
stranice, a Web lukovi odgovaraju hiperlinkovima koje interaguju sa Web
stranicama.
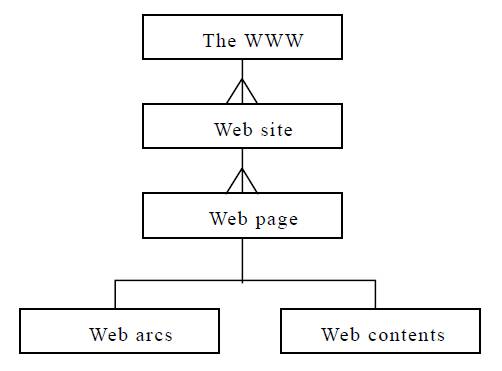
Šema World Wide Web-a
Na slici možemo da primetimo da pravougaonik predstavlja entitet, a linija
vezu. Trostruka linija označava odnos jedan-prema više. Linija na dnu
predstavlja generalizaciju ili specijalizaciju.
WWW možemo formalno da posmatramo kao diagraf sa (sekvenca od dva karaktera,
koji se pojavljuju u izvornom kodu) Web čvorovima i lukovima. Pristup
Web-u kao grafu može biti polazna tačka za generisanje strukture
World Wide Web-a koja se može koristiti za sajtove Web dizajnera,
pretraživače, Web crawler-e...
2.3 Terminologija Web strukture
U osnovi, Web može biti, kao što smo gore pomenuli, modelovan kao usmereni
graf koji sadrži skup čvorova koji su povezani sa usmerenim ivicama. U
narednim redovima daćemo kratak pregled terminologije koja se koristi
za modeliranje Web grafova:
• Web Grafikon(Graf) je usmereni graf koji predstavlja Web.
• Čvor - Svaka Web stranica je čvorište Web grafa.
• Link - svaki hiperlink na Web-u je usmerena ivica Web grafa.
• „Indegree“ - „indegree“ od čvora p je broj različitih
linkova koji ukazuju na p.
• „Outdegree“ - „outdegree“ od čvora p je broj
različitih linkova poreklom iz p koji ukazuje na druge čvorove.
• Direktna putanja - niz linkova koji počinju od strane p koji može da
stigne do stranice q(veza može da se prostire samo u jednom pravcu, odnosno
od svog izvora do njegove destinacije).
• Najkraća putanja - Od svih puteva između čvorova p i q, koji sadrži
najmanji broj linkova u sebi.
• Prečnik - maksimum svih najkraćih puteva izmedju para čvorova p i q
za sve parove čvorova p i q u Web grafu.
• Prosečna konektovana udaljenost - Prosečna dužina najkraće staze od
čvora p na čvor q za sve parove čvorova p i q.
3. Modeli znanja u analizi linkova
Istraživanja analize linkova, i to većina njih, počinju sa osnovnog modela na kojem se primenjuju različite mere. Ovi modeli se ili odnose na osnovnu jedinicu informacije ili na Web osobinu koja je primarna u aplikaciji.
3.1 Graph Structure Models – Graf modela struktura
U ovom odeljku ćemo razgovarati o osnovnim obrascima grafova koji predstavljaju različite osnovne koncepte i služe kao informacione jedinice dok rudare Web-om. Ovi obrasci mogu biti klasificirani u zavisnosti od toga da li je jedan čvor uključen, više čvorova, ili čitav niz čvorova koji učestvuju u obrazcu i sačinjavaju graf. Sledeći šabloni čine osnovu za najveći deo istraživanja u analizi linkova: jedan(single), i više(multiple) čvor modeli.
3.1.1 Single-Node Models – Single čvor modeli
Single - Node Models su strukture grafa koje se sastoje od jednog čvora i linkova koji upućuju na njih ili van njih.
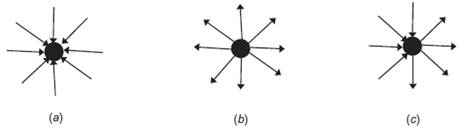
(a) čista autoritativna stranica,
(b) čista Hub stranica,
(c) tipična web stranica koja ima i hub rezultat i autoritet rezultat
povezan sa njom.
Neke stranice su korisnije za nastavak prelistavanja od drugih jer obezbeđuju
dobro organizovan skup izlaznih veza ka drugim stranicama koje pokrivaju
datu temu. Te stranice se nekad zovu koncentratori (hub).
S druge strane, stranice koje imaju mnogo dolaznih veza nazivaju se autoriteti
(authorities) jer postavljanje veze
ka nekoj stranici je način priznavanja vrednosti te stranice.
Dobar hub je onaj koji ukazuje na mnoge dobre autoritete, dok je dobra
autoratativna stranica ona na koju ukazuju mnogo dobri koncentratori(hub-ovi).
Pojmove hub-a i authority prvi je uveo priznati profesor računarstva Jon
Kleinberg.
3.1.2 Multiple - Node Models – Višestruki čvor modeli
Multiple – Node Models se bave sa graf strukturom koja sadrži skup čvorova i linkova koji je povezuju. U nastavku ćemo opisati neke od ovih modela i koncepte na koji se odražavaju:
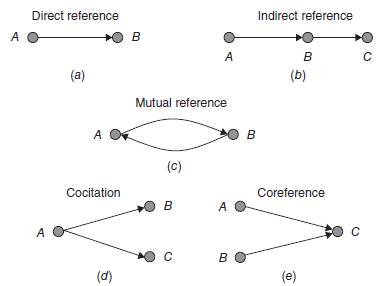
a) Direct reference - direktna referenca predstavlja
koncept gde čvor A ukazuje direktno na susedni čvor B, B je direktno referenciran
od strane A, što znaci da A i B mogu da imaju zajedničke teme i da mogu
biti povezane.
b) Indirect reference - Indirektna referenca
se odnosi na koncept gde čvor A ukazuje na B ili je direktno referenciran
od strane B, a čvor B ukazuje na čvor C ili je direktno referenciran od
strane C. U tom slučaju može se reći da je A indirektno referenciran od
strane čvora C, što može da znači da čvorovi A i C mogu biti povezani,
tačnije da mogu biti u nekoj relaciji.
c) Mutual Reference - Kada direktno dva čvora
A i B ukazuju jedan na drugi, tada se kaže da su ta dva čvora međusovno
referencirana. Ovo takođe ukazuje na snažnu relevantnost između dve stranice.
d) Co-Citation - Kada čvor A ukazuje na dva
čvora B i C, tada se kaže da čvor A ko-navodi(cociting) čvorove B i C.
Na Web-u, ovakva kocitacija može da ukazuje na sličnost između strana
B i C.
e) Co-Reference - Kada dva čvora B i C ukazuju
na čvor A, tada se kaže da je čvor A ko-referenciran od strane čvorova
B i C. Na Web-u, ovakva kocitacija ukazuje na sličnost između strana B
i C.
3.2 Markov Models - Markov model
U Markovom modelu, u lancu od m stanja sistema, evolucija sistema u budućnosti
zavisi samo od trenutnog stanja sistema i prošlih m-1 stanja sistema.
Prvog reda Markovi modeli su korišćeni za modeliranje ponašanja običnog
korisnika na Web-u. PageRank i randomized(nasumični) HITS(o kojima će
biti reči kasnije) koriste nasumično proces hoda zasnovan na Markovom
modelu. Korisnik nasumice bira ili skok na novu stranicu ili prati link.
Taj link predstavlja out-link u slučaju PageRank, a u slučaju „nasumičnog“
HITS-a, in-link ili out-link. Takođje je neophodno pomenuti da putem Markovog
modela se vrši modeliranje Web surfera, koji u suštini podrazumeva poprečne
linkove, što se značajno koristi u analizi linkova.
4. Algoritmi za analizu linkova
U ovom odeljku govorićemo o nekim popularnim i često korišćenim tehnikama za analizu u okviru Web domena. Algoritmi za obradu linkova mogu se svrstati na one koji se odnose na jednu stranu, ili na one koji se odnose na više strana. Predstavićemo neke od algoritama koji se odnose na jednu stranu, koji se najčešće koriste i koji su najuticajniji za analizu linkova.
4.1 HITS algoritam – Hyperlink-Induced Topic Search
Algoritam za otkrivanje autoriteta i koncentratora je - HITS algoritam
– Hyperlink-Induced Topic Search a njegov autor profesor računarstva Jon
Kleinberg.
HITS algoritam je algoritam za analizu linkova koji rangira Web stranice.
To je bila preteča PageRank-a.
Šema dodeljujе dve ocene za svaku stranicu: njen autoritet, koji procenjuje
vrednost sadržaja stranice, i njenu ,,hub” vrednost, koja procenjuje
vrednost svojih linkova ka drugim stranicama.
Osnova za HITS algoritam je koncept upravo navedenih čvorišta(koncentratora
– hub) i vlasti(authority). Glavni cilj algoritma je da pronađe hub-ove
i autoritete za web stranice vezane za određenu temu, koja se koristi
za identifikaciju stranica najrelevantnijih za tu temu. Neka je A matrica
susedstva takva da, ako postoji bar jedan hiperlink sa strane i na
strana j, onda Ai,j = 1, inače Ai,j = 0.

Vektori a* i h* odgovaraju glavnim „eigen“( vektor koji je
skaliran linearnom transformacijom, ali nije pomeren) vektorima AT A i
A AT. HITS algoritam je manje stabilan od Google – vog PageRank-a, koji
predlaže dva nova algoritma koji su modifikacija HITS algoritma, i imaju
bolje stabilnosti.
Prvi algoritam, koji se zove Randomized HITS, uvodi pristrasnost faktora
na osnovu vremenskog koraka (neparan ili paran), da bi odredio hub i authority
vrednnosti, tj, rezultate. Može se posmatrati kao slučajni surfer koji
baca novčić sa nagibom Î. Ovaj nagib je verovatnoća da će u bilo kom trenutku
surfer skočiti na novu stranicu, koja je slučajno izabrana. Sa verovatnoćom
1-Î, surfer će pratiti spoljašnji link ako je neparan vremenski korak
i pratiće unutrašnji link ako je paran vremenski korak. Autoritativna
težina stranice je šansa da surfer poseti stranicu na neparnom vremenskom
koraku t.
Drugi algoritam se zove Subspace HITS. Kod njega se authority i hub vrednosti
određuju podprostorom koji obuhvataju „eigen“ vektori umesto
pojedinačnih „eigen“ vektora. Nagibni faktor podprostora generisan
od strane „eigen“ vektora obezbeđuje više stabilnosti poremećajima
od originalnog HITS algoritma.
HITS je uspešan za upite u vezi tema koje su dobro zastupljene na Web-u
u smislu povezivanja gustine. Često, kada se upit odnosi na više fokusiranu
temu, HITS vraća rezultate za opštiju temu.
4.2 PageRank algoritam
PageRank je koncept dizajniran od strane Sergeja Brina i Lorenca
Pejdža - osnivača Google-a, sa ciljem određivanja relativne jačine neke
pojedinačne stranice na internetu u odnosu na sve ostale. PageRank se
izračunava na osnovu strukture linkova na internetu.
PageRank algoritam se zasniva na teoriji slučajnog hoda – random walk(matematička
formalizacija puta koji se sastoji od uzimanja slučajnih uzastopnih koraka)
po Markovom modelu. Algoritam obuhvata iterativno računanje PageRank mera,
za dati skup stranica. Ovo se takođe može izračunati korišćenjem matrica
izračunavanja slične HITS algoritmu. Razlika leži u unosu u matricu. Matrica
u PageRank algoritmu se sastoji od verovatnoće prelaza. (i, j)
vrednost elementa u matrici predstavlja verovatnoću da će link od stranice
i na stranicu j biti izabran. Dakle, za početne vrednosti
elementa (i, j) = 0, ne postoji veza sa strane i
na stranu j.

Vektor PR predstavlja globalni ranking svih N internet stranica u Web
grafu.
Kako u suštini funkcioniše algoritam? Pretpostavimo da se naš univerzum
sastoji od četiri stranice: A, B, C i D. Na početku pretpostavimo da su
sve stranice podjednako važne, pa im se dodeljuje PR (PageRank)
= 0.25 (Sve stranice zajedno imaće uvek vrednost 1).
Ako sve stranice (dakle, B, C i D) pokazuju samo stranicu A, onda će sve
tri stranice doprineti rangu stranica A sa svojih 0.25. Biće, dakle,
PR(A) = PR(B)+PR(C)+PR(D) = 0.75
Ako stranica C pokazuje samo stranicu A, stranica B pokazuje C i A, a
stranica D pokazuje sve tri stranice, onda se vrednost
doprinosa veze deli na sve veze koje izlaze sa te stranice. Biće, dakle,
PR(A) = PR(B)/2+PR(C)/1+PR(D)/3 = 0.125 + 0.25 + 0.083
Drugim rečima, PageRank koji ostvaruje jedna spoljašnja veza je jednak
vrednosti PageRank-a same te stranice kada se podeli sa normalizovanim
brojem spoljašnjih veza te stranice L( ) (pretpostavlja se da se veze
ka nekom određenom URL računaju samo jednom po dokumentu):
PR(A) = PR(B)/L(B)+PR(C)/L(C)+PR(D)/L(D)
Ili, u opštem slučaju:

tj. PageRank vrednost za stranicu u zavisi od vrednosti koju ima PageRank za sve stranice v iz skupa Bu (ovaj skup sadrži sve stranice koje pokazuju ka u) podeljen sa brojem L(v) veza koje polaze iz stranice v.
5. Primena(aplikacije) analize linkova
Analiza linkova se koristi u širokom spektru aplikacija. Ovo uključuje određivanje kvaliteta Web stranica vezanih za određenu temu, zatim klasifikacija Web strana u skladu sa temama, i druge funkcije kao što su Web puzanje(crawling), pronalaženje Web zajednica, izgradnja prilagođenih Web sajtova, personalizacija itd.
5.1 Web Page Ranking
Za Web Page Ranking se može reći da je najpoznatija aplikacija analize linkova. Da bi koristili ovu aplikaciju, tehnike kao što su PageRank ili HITS se primenjuju na web graf do raspodele verovatnoća preko svih Web stranica. Verovatnoća svake Web stranice odgovara svojem PageRank-u. Za vreme pretrage, Web stranice koje sadrže termine upita se vraćaju u opadajućem redosledu ovih verovatnoća.
5.2 Web Page Categorization
Cilj kategorizacija Web stranica je da se klasifikuju dokumenti Web-a
u određeni broj unapred definisanih kategorija.
Web Page Categorization određuje kategoriju ili klasu kojoj Web stranica
pripada, od unapred određenog skupa kategorija ili klasa. Pirolli definiše
skup od 8 kategorija za čvorove koji predstavljaju Web stranice i identifikuje
7 različitih funkcija na osnovu kojih se Web stranice mogu svrstati u
ovih 8 kategorija. Chakrabarti koristi “relaxation labeling technique”(metodologija
tretmana slike). Njen cilj je da poveže oznaku piksela date slike ili
čvorova datog grafa) da modelira klase uslovnih raspodela verovatnoća
za dodeljivanje kategorija posmatrajući susedne dokumente koji su povezani
sa datim dokumentom. Attardi predlaže automatski metod klasifikacije Web
strana na osnovu linka i konteksta. Ideja je da će link stranice, na koju
ukazuje druga stranica, imati težinu konteksta, jer izaziva nekoga da
pročita datu stranu sa stranice na koju se referencira.
5.3 Semantički web i socijalne mreže
Termin "semantički web" se odnosi na viziju W3C-a(The World
Wide Web Consortium) od Web povezanih podataka. Tehnologije semantičkog
web-a omogućavaju ljudima da stvore magacine podataka na Web-u i da pišu
pravila za rukovanje podacima. Povezani podaci su ovlašćeni od tehnologije,
kao što su RDF, SPARKL...
Podsticanjem uključivanja semantičkih sadržaja na Web stranicama, semantički
web ima za cilj pretvaranje trenutno Web nestrukturisanog dokumenata u
"web podatak". Ona se nadovezuje na Resource Description W3C
Framework (RDF).
Semantički Web je tako]e i omogućavanje tehnologije za snimanje znanja
modela socijalnih mreža. Oni se zajedno dopunjuju da pruže veoma korisnu
alatku za upravljanje socijalnim informacijama i interakcijama između
ljudi.
Hope vodi diskusiju o mehanizmu za integraciju podataka iz različitih
izvora na Web-u, koristeći Web rudarstvo(mining) da izvuče informacije
sa socijalne mreže.

Integracija izvora podataka za socijalne mreže
Na slici se uočava često sretani problem za integraciju podataka sa različitih
izvora. Linkovi koji nedostaju između Resource Description
Framevork-a (RDF) dokumenata ne obezbeđuju efikasan način za sumiranje
i razumevanje društvenih(socijalnih) modela. Kod semantičkog web-a ključni
izazov je integracija pouzdanih mreža i znanja o autoritetima tema.
Zaključak
U ovom radu, dali smo kratak uvod u ono što analiza linkova znači i njen
obim u odnosu na Web mining. Različite primene ove vrste analize
u okviru Web domena doveo je do brzog interesa u ovoj oblasti. Ovo je
dovelo do razvoja značajnih količina literature, izveštavanje o novim
tehnikama za analizu linkova kao i iskustvo u njihovom korišćenju.
Odeljci o modelima znanja i algoritmima pomogli su nam u klasifikaciji
istraživanja u oblasti analize linkova. Za svaki odeljak smo naveli stavke
koje spadaju u kategoriju istraživanja kojim se bavimo. Takođe smo dali
opis analize linkova u Web mining-u i naveli terminologiju koja se koristi
u Web strukturi. Na kraju smo predstavili metodologiju za primenu analize
linkova u aplikacijama, koja se može koristiti za dalje istraživanje u
ovoj oblasti.
Literatura
[1] Chapter
5. Link Analysis in Web Mining: Techniques and Applications, edited by:
Phillip C.-Y. Sheu, Heather Yu, C. V. Ramamoorthy, Arvind K. Joshi, Lotfi
A. Zadeh http://onlinelibrary.wiley.com/doi/10.1002/9780470588222.ch5/summary
[2] Hyperlink Analysis: Techniques and Applications (2002), by Prasanna
Desikan, Jaideep Srivastava, Vipin Kumar, Pang-Ning Tanhttp://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.101.6190
[3] Svet kompjutera – Iskopavanje podataka http://www.sk.rs/2005/05/skpr01.html
[4] Wikipedia – Dubinsko pretraživanje podataka
http://hr.wikipedia.org/wiki/Dubinsko_pretra%C5%BEivanje_interneta
[5] Web Structure Mining – Data Mining
http://www.web-datamining.net/structure/
[6] Web Structure Mining: An Introduction, by Miguel
Gomes da Costa Júnior Zhiguo Gong,Department of Computer and information
Science, Faculty of Science and Technology,University of Macau
http://www.ceng.metu.edu.tr/~nihan/ceng553/StudentPapers/01635156.pdf
[7] Hierarchical Web Structure Mining, Wookey LEE, †Faculty
of Computer Science, Sungkyul University
http://www.ieice.org/~de/DEWS/DEWS2006/doc/2A-v1.pdf
[8] Wikipedia – Graph theory http://en.wikipedia.org/wiki/Graph_theory
[9] Wikipedia - Markov model http://en.wikipedia.org/wiki/Markov_model
[10] Link Analysis Ranking: Algorithms, Theory,and Experiments
by Allan Borodin, Gareth O. Roberts, Jeffrey S. Rosenthal, Panayiotis
Tsaparas
http://www.cs.brown.edu/courses/csci2531/papers/toit.pdf
[11] Link Analysis Algorithms For Web Mining,
Tamanna Bhatia, Dept. of Computer Science, Desh
Bhagat Engineering College, Mandi Gobindgarh, Punjab, India http://www.ijcst.com/vol22/2/tamanna.pdf[12]
Hyperlink-Induced Topic Search (HITS)
[13] PageRank i Keyword Authority - Dva Najbitnija Faktora
SEO http://web-dizajn.blogspot.com/2008/05/pagerank-i-keyword-authority-dva.html
[14] Web Page Ranking Based on Text Content of Linked
Pages
http://www.ijcte.org/papers/115-G601.pdf[15] Automatic Web page categorization
by link and context analysis by G Attardi, A Gullì, F Sebastiani
http://www.mendeley.com/research/automatic-web-page-categorization-link-context-analysis/#
[16] Napredne metode u pronalaženju informacija, Cvetana
Krstev
[17] Integrating the Document Object Model with
Hyperlinks
for Enhanced Topic Distillation and Information Extraction, Soumen Chakrabarti,Indian
Institute of Technology Bombay
http://www10.org/cdrom/papers/pdf/p489.pdf
[18] Semantic Web http://www.w3.org/standards/semanticweb/
[19] Semantic Web – Main Page http://semanticweb.org/wiki/Main_Page
preuzmi
seminarski rad u wordu » » »
